Odds and ends

Since I last posted, there have been a number of small updates, but nothing that seemed big enough to write about. So I figured it might be worth posting a short summary of what I’ve been up to over the last couple of months.
In no particular order:
FOSDEM
I had the opportunity to visit FOSDEM for the first time last month. Saw lots of cool things, met lots of cool people and even managed to bag a LibreOffice hoodie. Most importantly, it was a chance to build friendships, which have a far higher value than any code ever will.
Wireless access points
I should probably write a proper post about this sometime, but a number of years ago we bought about 30 TP-LINK WR741ND wireless APs and slapped a custom build of OpenWRT on them. We installed the last spare a couple of months ago and ran into problems finding a decent replacement (specific hardware revisions can be quite difficult to find in Lebanon). After much searching, we managed to get ahold of a TP-LINK WR1043ND for testing and our OpenWRT build works great on it. Even better, it has a four-port gigabit switch which will give us much better performance than the old 100Mbps ones.
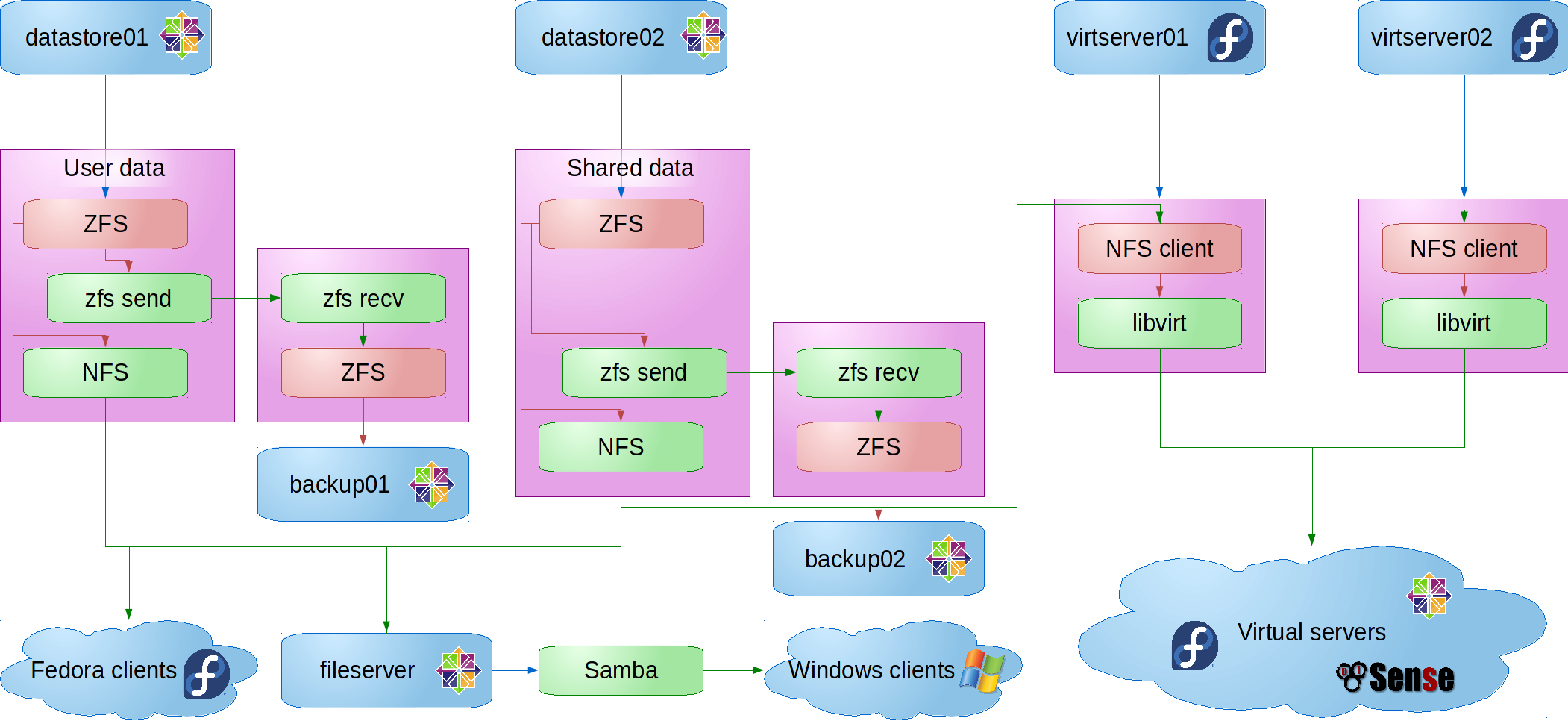
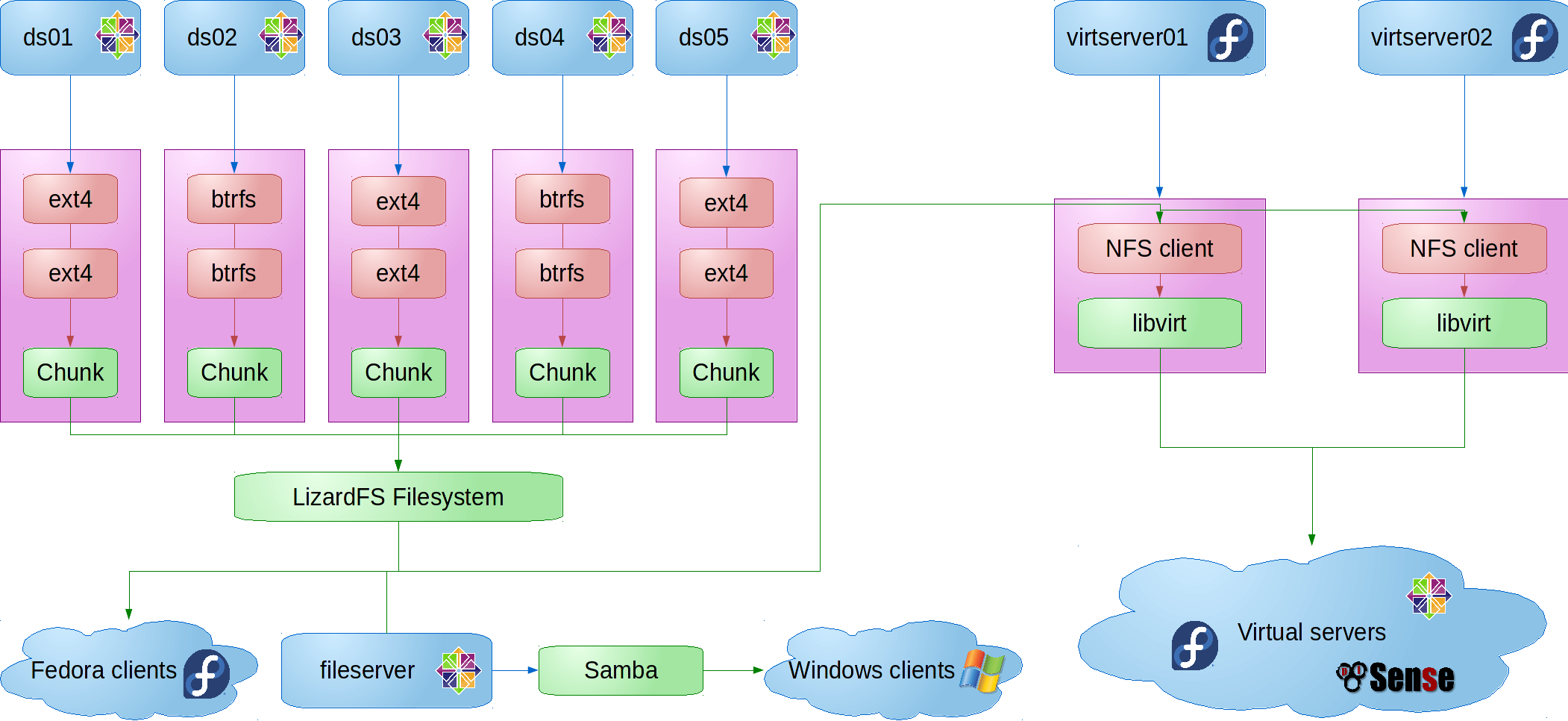
LizardFS patches
I ran into a couple of performance issues that I wrote some patches to fix. One is in the process of being accepted upsteam, while the other has been deemed too invasive, given that upstream would like to deal with the problem in a different way. For the moment, I’m using both on the school system, and they’re working great.
Kernel patch (tools count, right?)
After the F26 mass rebuild, I ran into problems building the USB/IP userspace tools with GCC 7. Fixing the bugs was relatively simple, and, since the userspace tools are part of the kernel git repository, I got to submit my first patches to the LKML. The difference between a working kernel patch and a good kernel patch can be compared to the difference between a Volkswagen Beetle and the Starship Enterprise. I really enjoyed the iterative process, and, after four releases, we finally had something good enough to go into the kernel. A huge thank you goes out to Peter Senna, who looked over my code before I posted it and made sure I didn’t completely embarrass myself. (Peter’s just a great guy anyway. If you ever get the chance to buy him a drink, definitely do so.)
Ancient history
As of about three weeks ago, I am teaching history. Long story as to how it happened, but I’m enjoying a few extra hours per week with my students, and history, especially ancient history, is a subject that I love. To top it off, there aren’t many places in the world where you can take your students on a field trip to visit the things you’re studying. On Wednesday, we did a trip to Nahr el-Kalb (the Dog River) where there are stone monuments erected by the ancient Assyrian, Egyptian, and Babylonian kings among others. I love Lebanon.