
btrfs on the server
As mentioned back here and here, our current server setup looks something like this:
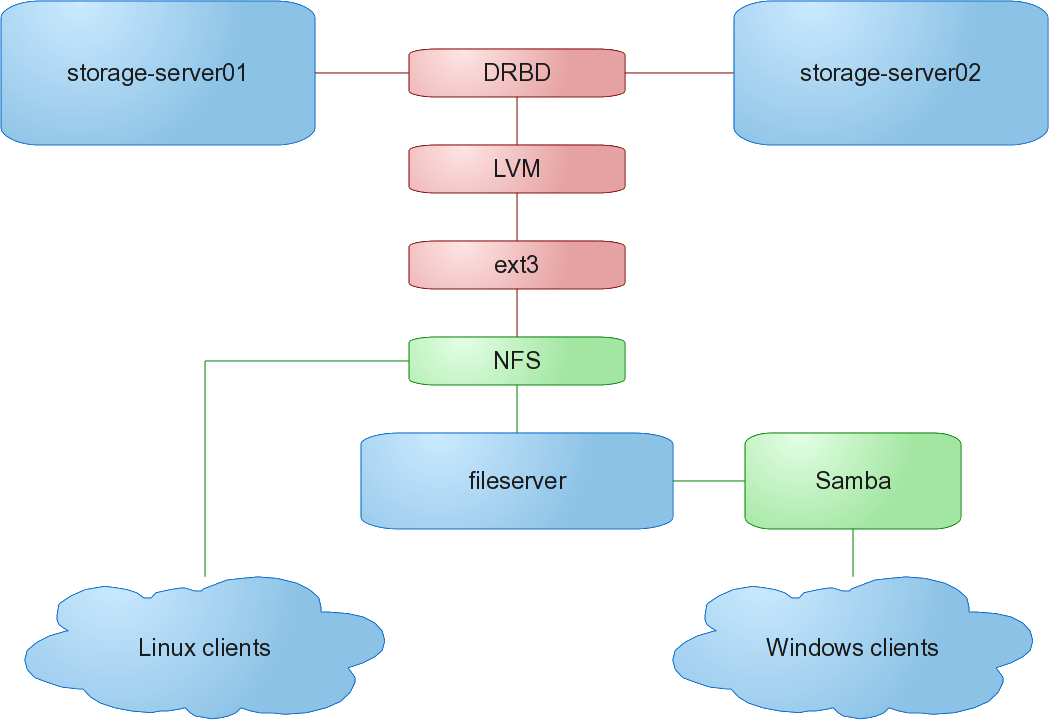
One thing not noted in the diagram is that fileserver, our dns server, ldap server, web server, and a few others all run as virtual machines on storage-server01 and storage-server02.
The drawback to this is that when disk io gets heavy, our virtual machines start struggling, even though they’re on separate hard drives.
Another problem with our current system is that we don’t have a good method of backup. Replication, yes, but if a student accidentally runs rm ./ -rf in their home directory, it’s gone.
So, with a bit of time over the summer after I’ve set up the school’s Fedora 13 image, I thought I’d tackle these problems. We now have three new “servers” (well, 2GB desktop systems with lots of big hard drives shoved in them). Our data has been split into three parts, and each server is primary for one part and backup for another.
The advantage? Now our virtual machines have full use of the (now misnamed) storage-servers01-2, both of which are still running CentOS 5.5. Our three new datastore servers, running Fedora 13, now share the load that was being put on one storage-server.
But this doesn’t solve the backup problem. A few years back, I experimented with LVM snapshots, but they were just way too slow. Ever since then, though, I’ve been very interested in the idea of snapshots and btrfs has them for free (at least in terms of extra IO, and I’m not too worried about space). Btrfs also handles multiple devices just fine, which means goodbye LVM. With btrfs, our new setup looks something like this:
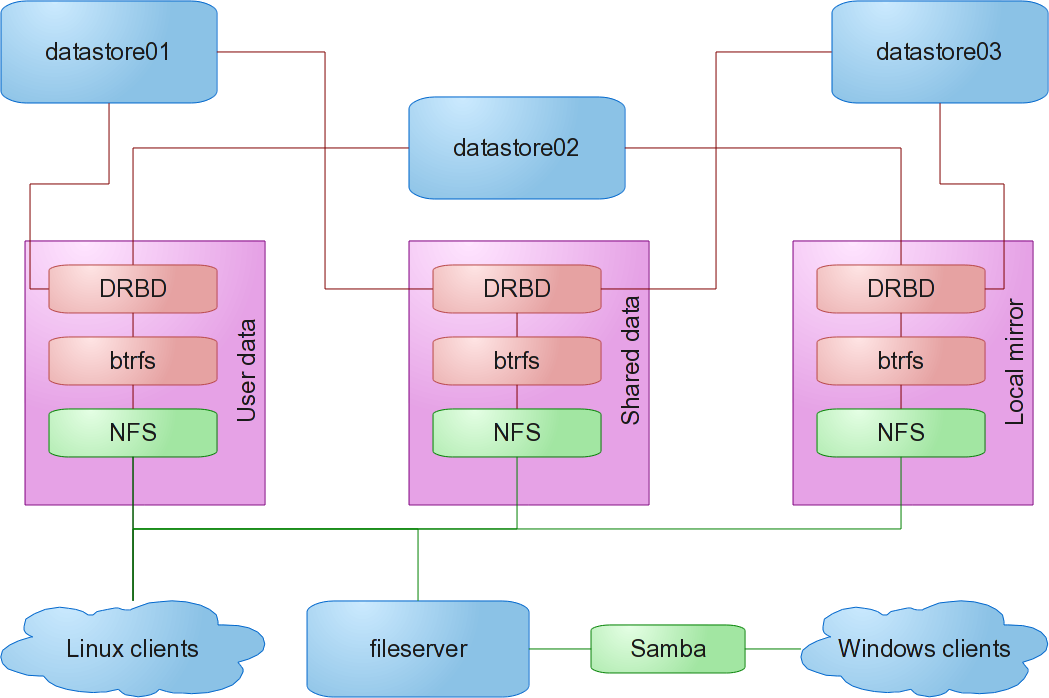
I have hit a couple of problems, though. By default, btrfs will RAID1 metadata if you have more than one device in a btrfs filesystem. I’m not sure whether my problem was related to this, but when I tried to manually balance the user filesystem which was spread across a 2TB and 1TB disk, I got -ENOSPC, a kernel panic, and a filesystem that was essentially read-only. This when the data on the drive was under 800GB (though most of the files are small hidden files in our users’ home directories). After checking out the btrfs wiki, I upgraded the kernel to the latest 2.6.34 available from koji (at that point in time), and then copied the data over to a newly created filesystem with RAID0 metadata and data (after all, my drives are already RAID1 using DRBD). A subsequent manual balance had no problems at all.
The second problem is not so easily solved. I wanted to do a speed comparison between our new configuration and our old one, so I ran bonnie++ on all of the computers in our main computer lab. I set it up so each computer was running their instance in a different directory on the nfs share (/networld/bonnie/$HOSTNAME).
Yes, I knew it would take a while (and stress-test the server), but that’s the point, right? The server froze after a few minutes. No hard drive activity. No network activity. The flashing cursor on the display stopped flashing (and, yes, it’s in runlevel 3). Num lock and caps lock don’t change color. Nothing in any logs. Frozen dead.
I rebooted the server, and tried the latest 2.6.33 kernel. After a few minutes of the stress test, it was doing a great imitation of an ice cube. I tried a 2.6.35 Fedora 14 kernel rebuilt for Fedora 13 that I had discarded because of a major drop in DRBD sync speed. This time the stress test barely made it 30 seconds.
So where does that leave me? Tomorrow I plan on running the stress test on our old CentOS server. If it freezes too, then I’m not going to worry too much. It hasn’t ever frozen like that with normal use, so I’ll just put it down to NFS disliking 30+ computers writing gigabytes of data at the same time. I did file this bug report, but not sure if I’ll hear anything on it. It’s kind of hard to track down a problem if there aren’t any error messages on screen or in the logs.
The good news is that I do have daily snapshots set up, shared read-only over NFS, that get deleted after a week. So now we have replication and backups.
I’d like to keep this configuration, but that depends on whether the server freeze bug will show up in real-world use. If it does, we’ll go back to CentOS on the three servers, and probably use ext4 as the base filesystem.
Update: 08/26/2010 After adding a few boot options, I finally got the logs of the freeze from the server. It looks like it’s a combination of relatively low RAM and either a lousy network card design or a poor driver. Switching the motherboard has mitigated the problem, and I’m hoping to get some more up-to-date servers with loads more RAM.