
From NFS to LizardFS
If you’ve been following me for a while, you’ll know that we started our data servers out using NFS on ext4 mirrored over DRBD, hit some load problems, switched to btrfs, hit load problems again, tried a hacky workaround, ran into problems, dropped DRBD for glusterfs, had a major disaster, switched back to NFS on ext4 mirrored over DRBD, hit more load problems, and finally dropped DRBD for ZFS.
As of March 2016, our network looked something like this:
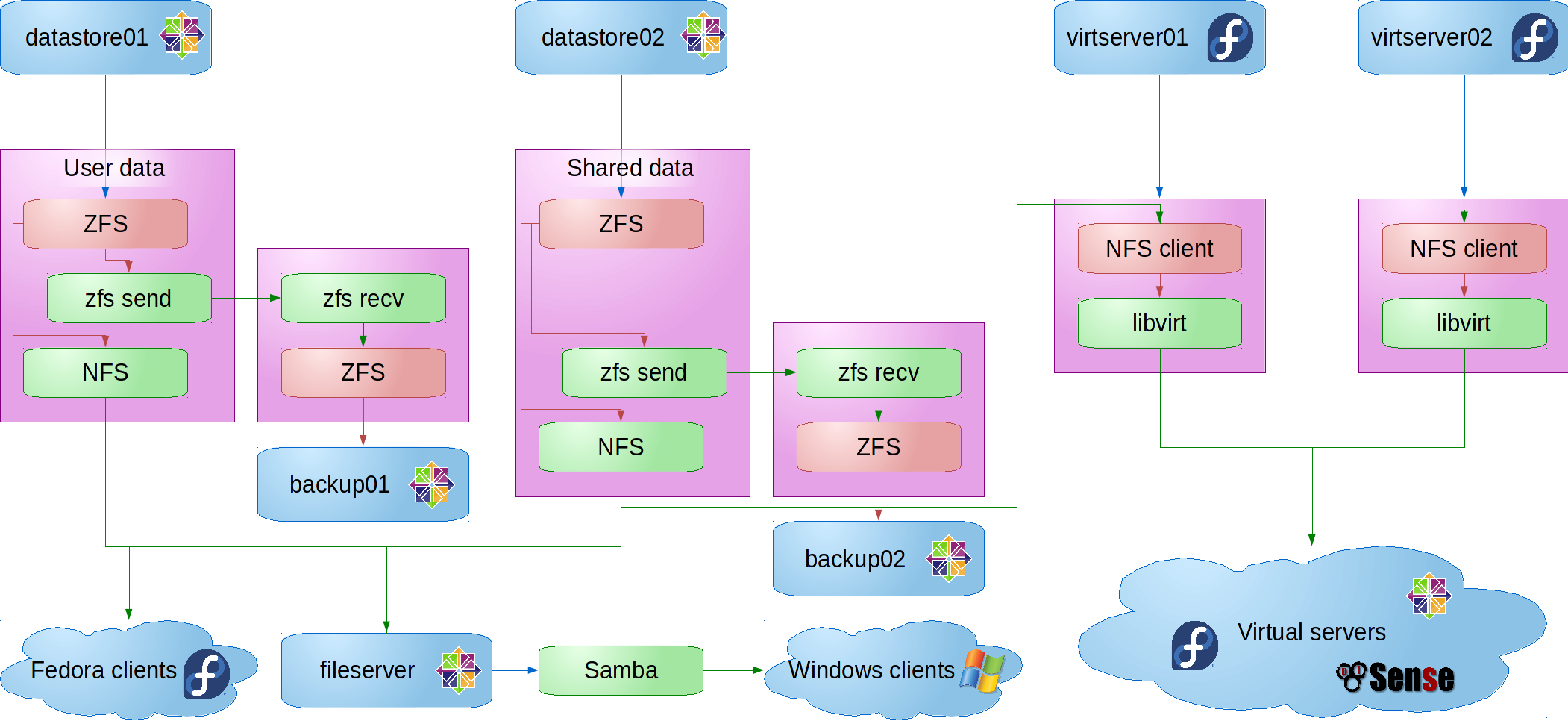
Our NFS over ZFS system worked great for three years, especially after we added SSD cache and log devices to our ZFS pools, but we were starting to overload our ZFS servers and I realized that we didn’t really have any way of scaling up.
This pushed me to investigate distributed filesystems yet again. As I mentioned here, distributed filesystems have been a holy grail for me, but I never found one that would work for us. Our problem is that our home directories (including config directories) are stored on our data servers, and there might be over one hundred users logged in simultaneously. Linux desktops tend to do a lot of small reads and writes to the config directories, and any latency bottlenecks tend to cascade. This leads to an unresponsive network, which then leads to students acting out the Old Testament practice of stoning the computer. GlusterFS was too slow (and almost lost all our data), CephFS still seems too experimental (especially for the features I want), and there didn’t seem to be any other reasonable alternatives… until I looked at LizardFS.
LizardFS (a completely open source fork of MooseFS) is a distributed filesystem that has one fascinating twist: All the metadata is stored in RAM. It gets written out to the hard drive regularly, but all of the metadata must fit into the RAM. The main result is that metadata lookups are rocket-fast. Add to that the ability to direct different paths (say, perhaps, config directories) to different storage types (say, perhaps, SSDs), and you have a filesystem that is scalable and fast.
LizardFS does have its drawbacks. You can run hot backups of your metadata servers, but only one will ever be the active master at any one time. If it goes down, you have to manually switch one of the replicas into master mode. LizardFS also has a very complicated upgrade procedure. First the metadata replicas must be upgraded, then the master and finally the clients. And finally, there are some corner cases where replication is not as robust as I would like it to be, but they seem to be well understood and really only seem to affect very new blocks.
So, given the potential benefits and drawbacks, we decided to run some tests. The results were instant… and impressive. A single user’s login time on a server with no load… doubled. Instead of five seconds, it took ten for them to log in. Not good. But when a whole class logged in simultaneously, it took only 15 seconds for them to all log in, down from three to five minutes. We decided that a massive speed gain in the multiple user scenario was well worth the speed sacrifice in the single-user scenario.
Another bonus is that we’ve gone from two separate data servers with two completely different filesystems (only one which ever had high load) to five data servers sharing the load while serving out one massive filesystem, giving us a system that now looks like this:
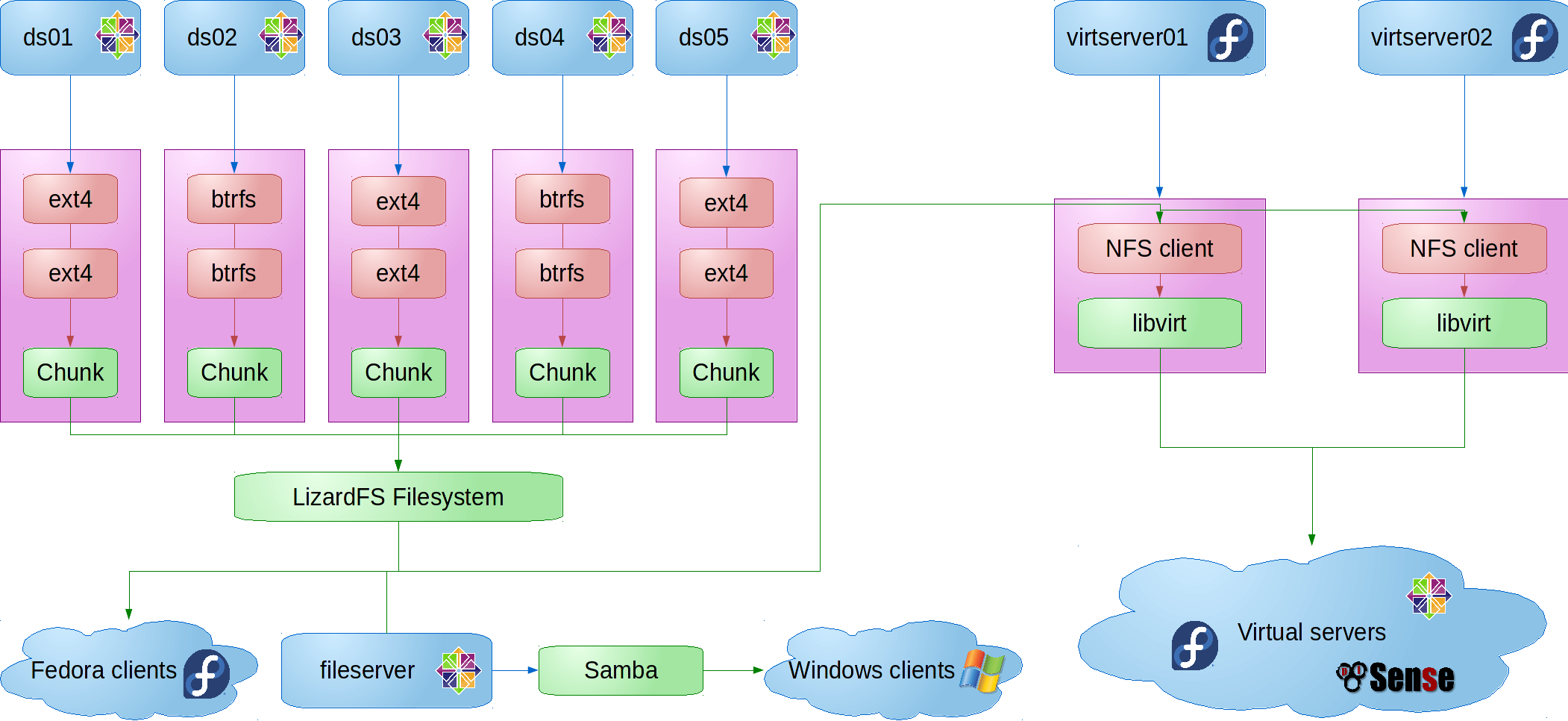
So, six months on, LizardFS has served us well, and will hopefully continue to serve us for the next (few? many?) years. The main downside is that Fedora doesn’t have LizardFS in its repositories, but I’m thinking about cleaning up my spec and putting in a review request.
Updated to add graphics of old and new server layouts, info about Fedora packaging status, LizardFS bug links, and remove some grammatical errors
Updated 12 April 2017 I’ve just packaged up LizardFS to follow Fedora’s guidelines and the review request is here.
Comments
q2dg
Sunday, Apr 9, 2017
Jonathan Dieter
Wednesday, Apr 12, 2017
Eddie Cheng
Sunday, Jul 23, 2017
Matt B
Tuesday, Jul 24, 2018
Hello,
Wonder why you are not using NetApp or Spectrascale (gpfs?) We use both and lustre (ddn) for our scratch over IB. Spectrascale is very fast using the native client with accessibility using CNFS mode.
Jonathan Dieter
Tuesday, Jul 24, 2018