
Under the hood

Two years ago, as mentioned in btrfs on the server, we set up btrfs as our primary filesystem on our data servers. After we started running into high load as our network expanded (and a brief experiment with GlusterFS as mentioned in GlusterFS Madness), in March we switched over to ext4 with the journal on an SSD.
So, as of March, we had three data servers. datastore01 was the primary server for usershare, our shared data. datastore03 was the primary server for users, which, surprisingly, held our users’ home directories. datastore02 was secondary for both usershare and users which were synced using DRBD.
One of the things I had originally envisioned when I set up our system was a self-correcting system. I played around with both the Red Hat Cluster suite and heartbeat and found that they were a bit much for what we were trying to achieve, but I wanted a system where, if a single data server went down, the only notice I would have would be a Nagios alert, and not a line of people outside my office asking me what the problem is.
While I never achieved that level of self correction, I could switch usershare from datastore01 to datastore02 with a less than 30-second delay, and the same applied with switching users from datastore03 to datastore02. NFS clients would connect to an aliased IP that switched when the filesystem switched, so they would only freeze for about 30 seconds, and then come back.
This made updating the systems pretty painless. I would update datastore02 first, reboot into the new kernel and verify that everything was working correctly. Then, I would migrate usershare over to datastore02 and update datastore01. After datastore01 came back up, I would migrate usershare back, and then repeat the process with users and datastore03.
We also had nightly rsync backups to backup01 which was running btrfs and which would create a snapshot after the backup finished. We implemented nightly backups after a ham-fisted idiot of a system administrator (who happens to sleep next to my wife every night) managed to corrupt our filesystem (and, coincidentally, come within a hair’s breadth of losing all of our data) back when we were still using btrfs. The problem with DRBD is that it writes stuff to the secondary drives immediately, which is great when you want network RAID, but bad when the corruption that you just did on the primary is immediately sent to the secondary. Oops. Anyhow, after we managed to recover from that disaster (with lots of prayer and a very timely patch from Josef Bacik), we decided that a nightly backup to a totally separate filesystem wouldn’t be a bad idea.
We also had two virtual hosts, virtserver01 and virtserver02. Our virtual machines’ hard drives were synced between the two using DRBD. We could stop a virtual machine on one host and start it on the other, but live migration didn’t work and backups were a nightly rsync to backup01.
So, after the switchover, our network looked something like this (click for full size):
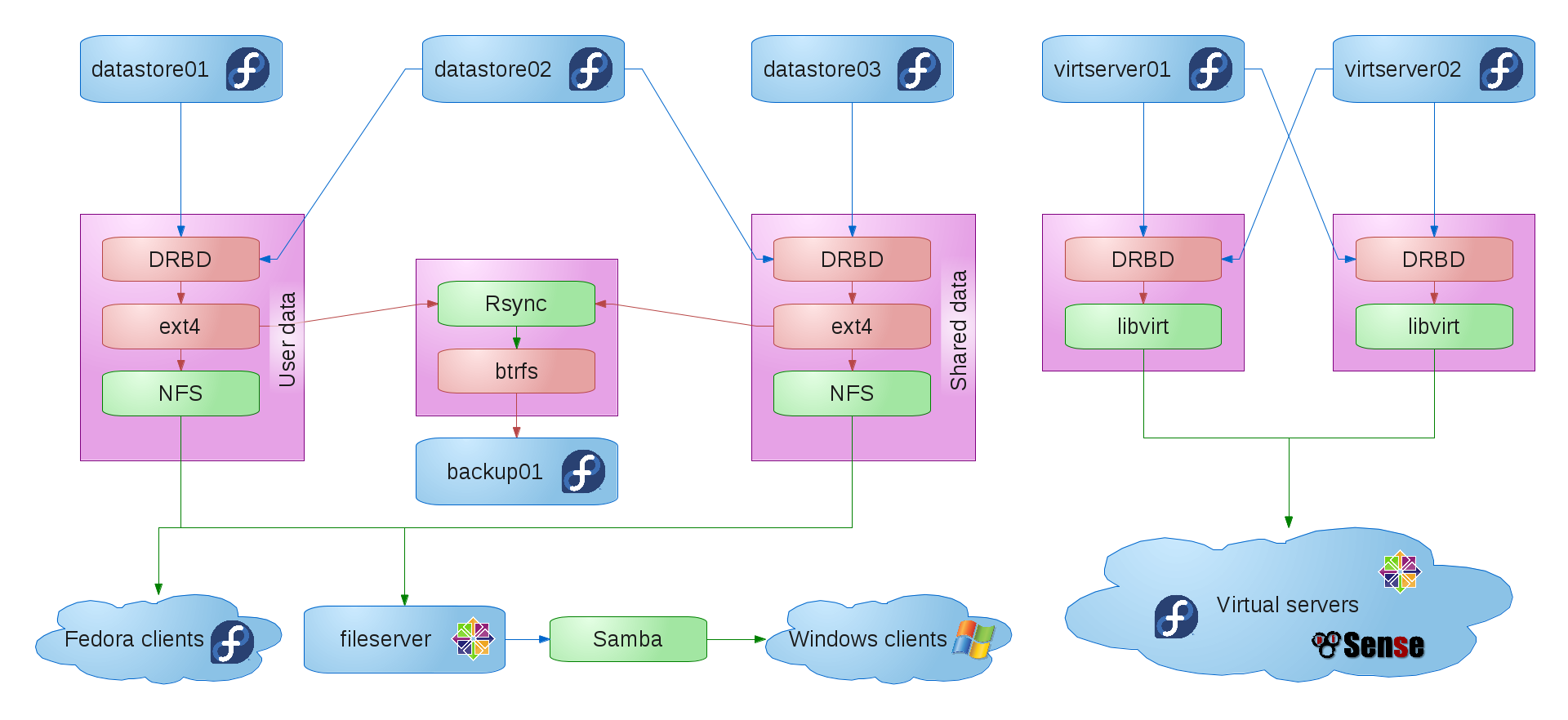
I was pretty happy with our setup, but our load problem popped up again. While it was better than it was before the switch, it would still sometimes peak during breaks and immediately after school.
As I was asking myself what other system administrators do, it hit me that one of my problems was my obsession with self-correcting systems. More specifically, my obsession with automatic correction of a misbehaving server, rather than the more common issue of automatically “correcting” misbehaving hard drives. Because of that, I had been ignoring NAS’s as none of them seemed to have something that worked along the same lines as DRBD.
I started looking at FOSS NAS solutions, and found NAS4Free, a FreeBSD appliance that comes with the latest open-source version of ZFS. The beauty of ZFS when it comes to speed is that, unlike btrfs, it allows you to set up a SSD as a read cache or as the data log.
After running some tests over the summer, I found that ZFS with a SSD cache partition and SSD log partition was quite a bit faster than our ext4 partitions with SSD log, especially with multiple systems hitting the server at the same time with multiple small writes.
So we switched our data servers over to NAS4Free, reduced them to two, and added another backup server. The data servers are configured with RAIDZ1 plus SSD caches and logs. The backups are configured with RAIDZ1, no cache, no SSD log.
A nice feature of ZFS (which I believe btrfs also recently got) is the ability to send a diff between two snapshots from one server to another. Using this feature (which isn’t exposed in the NAS4Free web interface, but accessible using a bash script that runs at 2:00 every morning), I’m able to send my backups to the backup servers in far less time than it used to take to run rsync.
One other nice feature of NAS4Free is the ability of ZFS to create a “volume” which is basically a disk device as part of the data pool, and then export it using iSCSI. I switched our virtual machines’ hard drives from DRBD to iSCSI, which now allows us to live migrate from one virtual host to the other. We also get the bonus of automatic backups of the ZFS volumes as part of the snapshot diffs.
Now our network looks something like this (click for full size):
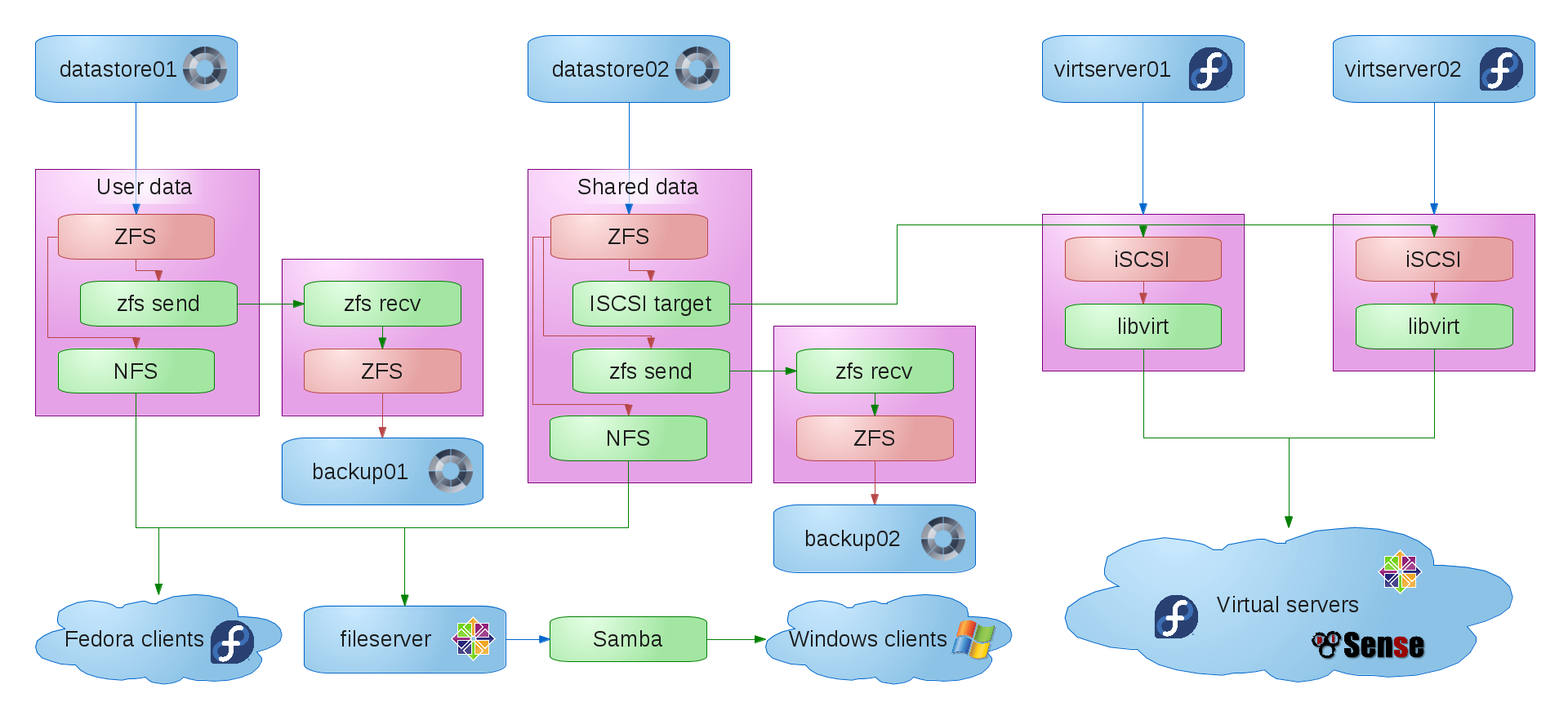
There is one major annoyance and one major regression in our system, though. First the annoyance. ZFS has no way of removing a drive. You can swap out a drive in a RAIDZ or mirror set, but once you’ve added a RAIDZ set, a mirror or even a single drive, you cannot remove them without destroying the pool. Apparently enterprise users never want to shrink their storage. More on this in my next post.
The major regression is that if either of our data servers goes down, the whole network goes down until I get the server back up. I can switch us over to the backups, but we’ll be using yesterday’s data if I do, so that’s very much a last resort. This basically means that I need to be ready to swap the drives into a new system if one of our data servers does go down. And there will be downtime if (when?) that happens. Joy.
So now we have a system that gives us the speed we need, but not the redundancy I’d like. What I’d really like would be a filesystem that is fully distributed, has no single point of failure and allows you to store volumes on it. GlusterFS fits the bill (mostly), but I’m gunshy at the moment. Ceph looks like it may fit the bill even better with RBD as well as CephFS, but the filesystem part isn’t considered production-ready yet.
So where does that leave us? As we begin the 2012-2013 school year, file access and writing is faster than ever. We’d need simultaneous failure of four hard drives before we start losing data, and, once I deploy our third backup server for high-priority data, it will take even more to lose the data. We do have a higher risk of downtime in the event of a server failure, but we’re not at the point where that downtime would keep us from our primary job, teaching.
Comments
Mark T. Kennedy
Thursday, Sep 13, 2012
Jonathan Dieter
Thursday, Sep 13, 2012
We have somewhere around 100 Fedora systems actively accessing the data at any one time. We use NFS for our home directories, so the server gets hit pretty hard, especially if we have a whole class logging in at the same time.
I have looked at ceph (I think I took my first look at it a couple of years ago before it was even in the Linux kernel). Honestly, it’s exactly what I want, but the POSIX filesystem isn’t stable enough yet for me to risk our data on it. :(
YS
Friday, Sep 14, 2012
Jonathan Dieter
Thursday, Nov 1, 2012