Small file performance on distributed filesystems - Round 2

Last year, I ran some benchmarks on the GlusterFS, CephFS and LizardFS distributed filesystems, with some interesting results. I had a request to redo the test after a LizardFS RC was released with a FUSE3 client, since it is supposed to give better small file performance.
I did have a request last time to include RozoFS, but, after a brief glance at the documentation, it looks like it requires a minimum of four servers, and I only had three available. I also looked at OrangeFS (originally PVFS2), but it doesn’t seem to provide replication, and, in preliminary testing, it was over ten times slower than the alternatives. NFS was tested and its results are included as a baseline.
I once again used compilebench, which was designed to emulate real-life disk usage by creating a kernel tree, reading all the files in the tree, simulating a compile of the tree, running make clean, and finally deleting the tree.
The test was much the same as last time, but with one important difference. Last time, the clients were running on the same machines that were running the servers. LizardFS benefited hugely from this as it has a “prefer local chunkserver” feature that will skip the network completely if there’s a copy on the local server. This time around, the clients were run on completely separate machines from the servers, which removed that advantage for LizardFS, but which I believe is a better reflection on how distributed filesystems are generally used.
I would like to quickly note that there was very little speed difference between LizardFS’s FUSE2 and FUSE3 clients. The numbers included are from the FUSE3 client, but they only differed by a few percentage points from the FUSE2 client.
A huge thank you to my former employer, the Lebanon Evangelical School for Boys and Girls, for allowing me to use their lab for my test. The test was run on nine machines, three running as servers and six running the clients. The three servers operated as distributed data servers with three replicas per file. Each client machine ran five clients, giving us a simulated 30 clients.
All of the data was stored on XFS partitions on SSDs for speed, except for CephFS, which used an LVM partition with Bluestore. After running the benchmarks with one distributed filesystem, it was shut down and its data deleted, so each distributed filesystem had the same disk space available to it.
The NFS server was setup to export its shares async (for speed). The LizardFS clients used the recommended mount options, while the other clients just used the defaults (the recommended small file options for GlusterFS caused the test to hang). CephFS was mounted using the kernel module rather than the FUSE filesystem.
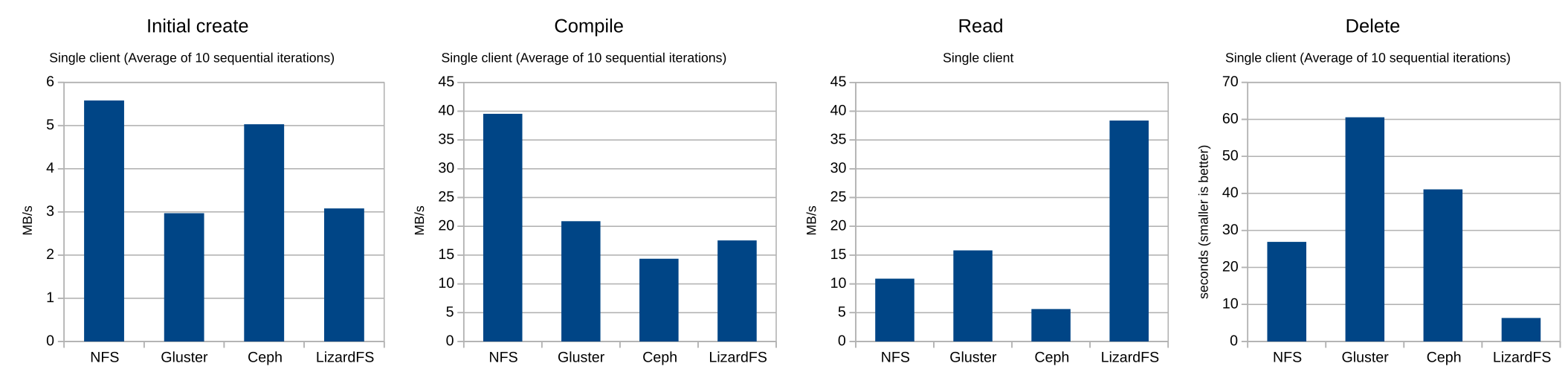
Before running the 30 clients simultaneously, I ran the test ten times in a row on a single client, to get a single client baseline. So let’s look at this performance (click for the full-size chart):

So, apart from the simulated “make clean”, CephFS dominated these tests. It even managed to beat out NFS on everything except clean and delete, and delete was within a couple of seconds. LizardFS and GlusterFS were close in most of the tests with LizardFS taking a slight lead. GlusterFS, though, was much slower than the alternatives when it came to the delete test, which is consistent with last year’s test.
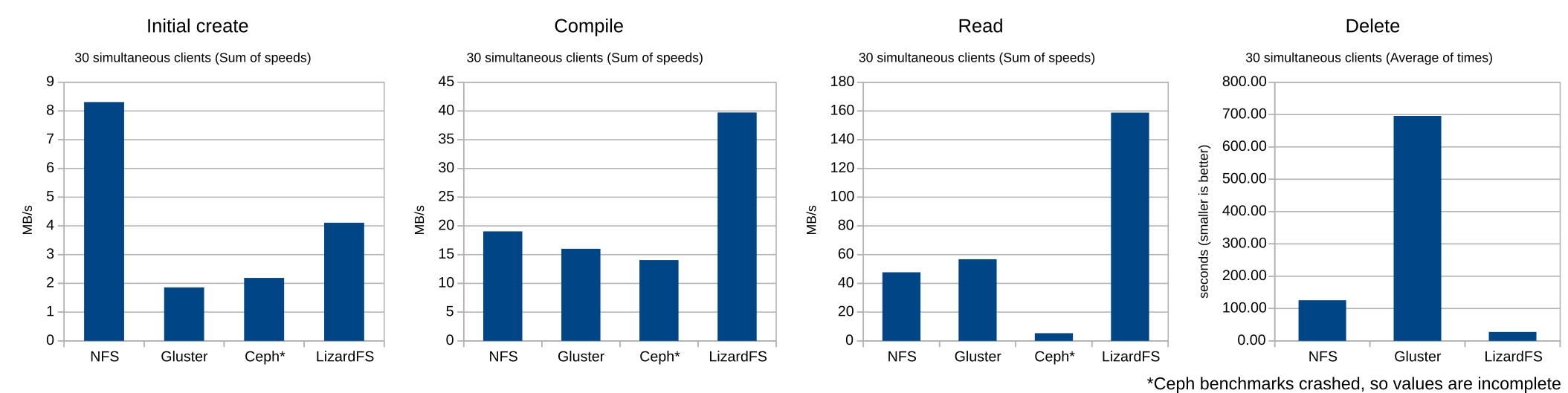
Next, let’s look at multiple-client performance. With these tests, I ran 30 clients simultaneously, and, for the first four tests, summed up their speeds to give me the total speed that the server was giving the clients. Because deletions were running simultaneously, I averaged the time for the final test.

Ok, just wow. If you’re reading and writing large numbers of small files, NFS is probably still going to be your best bet. It was over five times faster than the competition in writing and over twice as fast in reading. The compile process is where things started to change, with both CephFS and LizardFS beating NFS, and LizardFS took a huge lead in the clean test and delete test. Interestingly, it took just 50% longer for LizardFS to delete 30 clients’ files compared with a single client’s files.
After CephFS’s amazing performance in the single-client mode, I was looking forward to some incredible results, but it really didn’t scale as well as I had hoped, though it was still competitive with the other distributed filesystems. Once again, LizardFS has shown that when it comes to metadata operations, it’s really hard to beat, but its aggregate read and write performance were disappointing. And, once again, GlusterFS really struggled with the test. I wish it would have worked with the performance tuning for small files enabled, as we might have seen better results.