
Benchmarking small file performance on distributed filesystems

Update 2018-07-23: There are new benchmarks here
As I mentioned in my last post, I’ve spent the last couple of weeks doing benchmarks on the GlusterFS, CephFS and LizardFS distributed filesystems, focusing on small file performance. I also ran the same tests on NFSv4 to use as a baseline, since most Linux users looking at a distributed filesystem will be moving from NFS.
The benchmark I used was compilebench, which was designed to emulate real-life disk usage by creating a kernel tree, simulating a compile of the tree, reading all the files in the tree, and finally deleting the tree. I chose this benchmark because it does a lot of work with small files, very similar to what most file access looks like in our school. I did modify the benchmark to only do one read rather than the default of three to match the single creation, compilation simulation and deletion performed on each client.
The benchmarks were run on three i7 servers with 32GB of RAM, connected using a gigabit switch, running CentOS 7. GlusterFS is version 3.8.14, CephFS is version 10.2.9, and LizardFS is version 3.11.2. For GlusterFS, CephFS and LizardFS, the three servers operated as distributed data servers with three replicas per file. I first had one server connect to the distributed filesystem and run the benchmark, giving us the single-client performance. Then, to emulate 30 clients, each server made ten connections to the distributed filesystem and ten copies of the benchmark were run simultaneously on each server.
For the NFS server, I had to do things differently because there are apparently some major problems with connecting NFS clients to a NFS server on the same system. For this one, I set up a fourth server that operated just as a NFS server.
All of the data was stored on XFS partitions on SSDs for speed. After running the benchmarks with one distributed filesystem, it was shut down and its data deleted, so each distributed filesystem had the same disk space available to it.
The NFS server was setup to export its shares async (also for speed). The LizardFS clients used the recommended mount options, while the other clients just used the defaults (I couldn’t find any recommended mount options for GlusterFS or CephFS). CephFS was mounted using the kernel module rather than the FUSE filesystem.
So, first up, let’s look at single-client performance (click for the full-size chart):
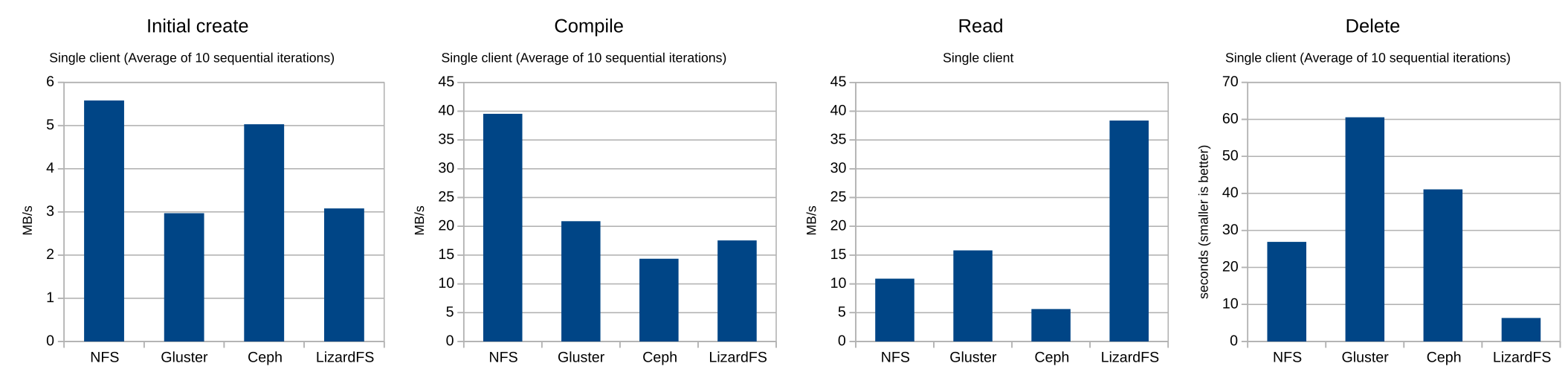
Initial creation didn’t really have any surprises, though I was really impressed with CephFS’s performance. It came really close to matching the performance of the NFS server. Compile simulation also didn’t have many surprises, though CephFS seemed to start hitting performance problems here. LizardFS initially surprised me in the read benchmark, though I realized later that the LizardFS client will prioritize a local server if the requested data is on it. I have no idea why NFS was so slow, though. I was expecting NFS reads to be the fastest. LizardFS also did really well with deletions, which didn’t surprise me too much. LizardFS was designed to make metadata operations very fast. GlusterFS, which did well through the first three benchmarks, ran into trouble with deletions, taking almost ten times longer than LizardFS.
Next, let’s look at multiple-client performance. With these tests, I ran 30 clients simultaneously, and, for the first three tests, summed up their speeds to give me the total speed that the server was giving the clients. CephFS ran into problems during its test, claiming that it had run out of disk space, even though (at least as far as I could see) it was only using about a quarter of the space on the partition. I went ahead and included the numbers generated before the crash, but I would take them with a grain of salt.
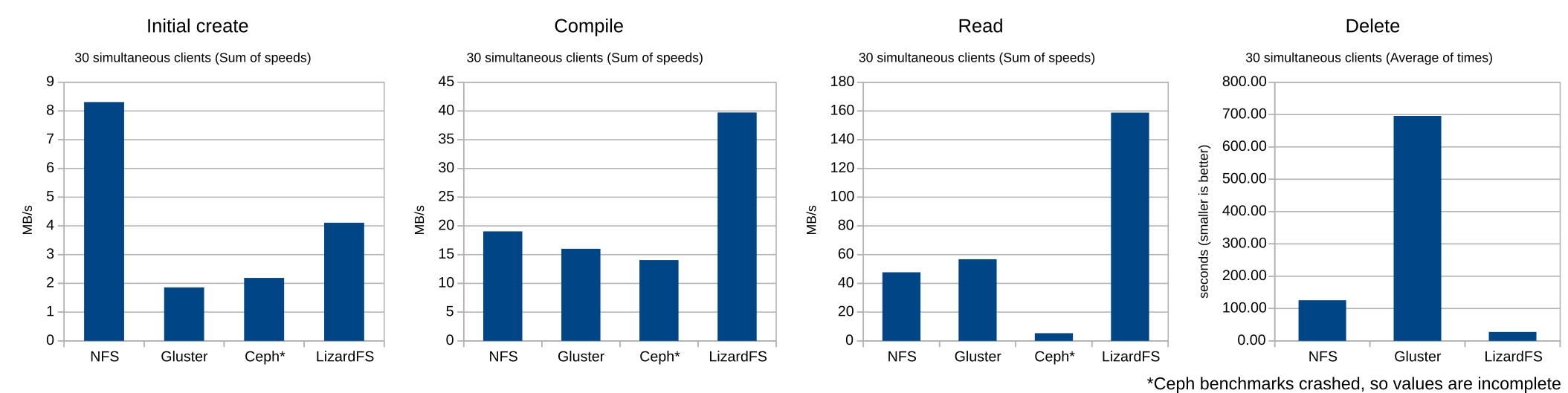
Once again, initial creation didn’t have any major surprises, though NFS did really well, giving much better aggregate performance than it did in the earlier single-client test. LizardFS also bettered its single-client speed, while GlusterFS and CephFS both were slower creating files for 30 clients at the same time.
LizardFS started to do very well with the compile benchmark, with an aggregate speed over double that of the other filesystems. LizardFS flew with the read benchmark, though I suspect some of that is due to the client preferring the local data server. GlusterFS managed to beat NFS, while CephFS started running into major trouble.
The delete benchmark seemed to be a continuation of the single-client delete benchmark with LizardFS leading the way, NFS just under five times slower, and GlusterFS over 25 times slower. The CephFS benchmarks had all failed by this point, so there’s no data for it.
I would be happy to re-run these tests if someone has suggestions on optimizations especially for GlusterFS and CephFS.
Comments
Josh Boon
Monday, Aug 14, 2017
Jonathan Dieter
Monday, Aug 21, 2017
Sorry for the delay. The output of “gluster volume info gv0” is:
EDIT: Sorry, just saw that you asked for a bit more than just my gluster configuration. For all the tests except NFS, I had three servers storing three replicas and ten clients running simultaneously on each server for the 30-client tests. The servers were connected to each other using a 1GB Mikrotik switch. If you need any other details, please ask.
low
Monday, Aug 21, 2017
Jonathan Dieter
Friday, Aug 25, 2017
low
Friday, Aug 25, 2017