
Creating a multi-region Wireguard VPN in AWS

On January 2nd, 2020, I started as the Head of Software Services at Spearline, an audio quality testing company based out of Skibbereen, Ireland. At Spearline, most of our infrastructure is in Amazon’s cloud, but we do have over a hundred callservers around the world. These servers are the ones that actually place the phone calls that we use to check the audio quality on the lines that we’re testing. One of my tasks is to improve security, and one way I’ve done that is to move our callservers behind a VPN that’s connected to our primary Amazon VPC.
Now, to give a bit of background, most of our work and all of our data processing happens in the eu-west-1 region, but we do actually have VPCs with one or two servers setup in most of the available AWS regions. These regions are connected with all other regions with a Peering Connection, which allows us to, for example, have a server in Singapore connect to one of our servers in Ireland using private IP addresses only.
The problem is that we have many callservers that aren’t in AWS, and, traditionally, these servers would have been whitelisted in our infrastructure based on their public IP address. This meant that we sometimes had unencrypted traffic passing between our callservers and the rest of our infrastructure, and that there was work to do when a callserver changed its public IP address. It looked like the best solution was to setup a Wireguard VPN server and have our callservers connect using Wireguard.
Since the VPN server was located in eu-west-1, this had the unfortunate side effect of dramatically increasing the latency between the callserver and servers in other regions. For example, we have a non-AWS callserver located in Singapore that was connecting to a server in the AWS region ap-southeast-1 (Singapore) to figure out where it was supposed to call. The latency between the two servers was about 3 ms, but when going through our VPN server in Ireland, the latency jumped to almost 400ms.
The other problem is that Amazon VPC peering agreements do not allow you to forward traffic from a non-VPC private IP address. So, if the private IP range for our Ireland VPC was 10.2.0.0/16 and the private range for our callservers was 10.50.0.0/16, Singapore would only allow traffic coming from the Ireland VPC if it was from 10.2.0.0/16 and drop all traffic originating from a VPN client. AWS does allow you to create Transit Gateways that will allow extra ranges through, but they cost roughly $36 a month per region, which was jacking up the cost of this project significantly.
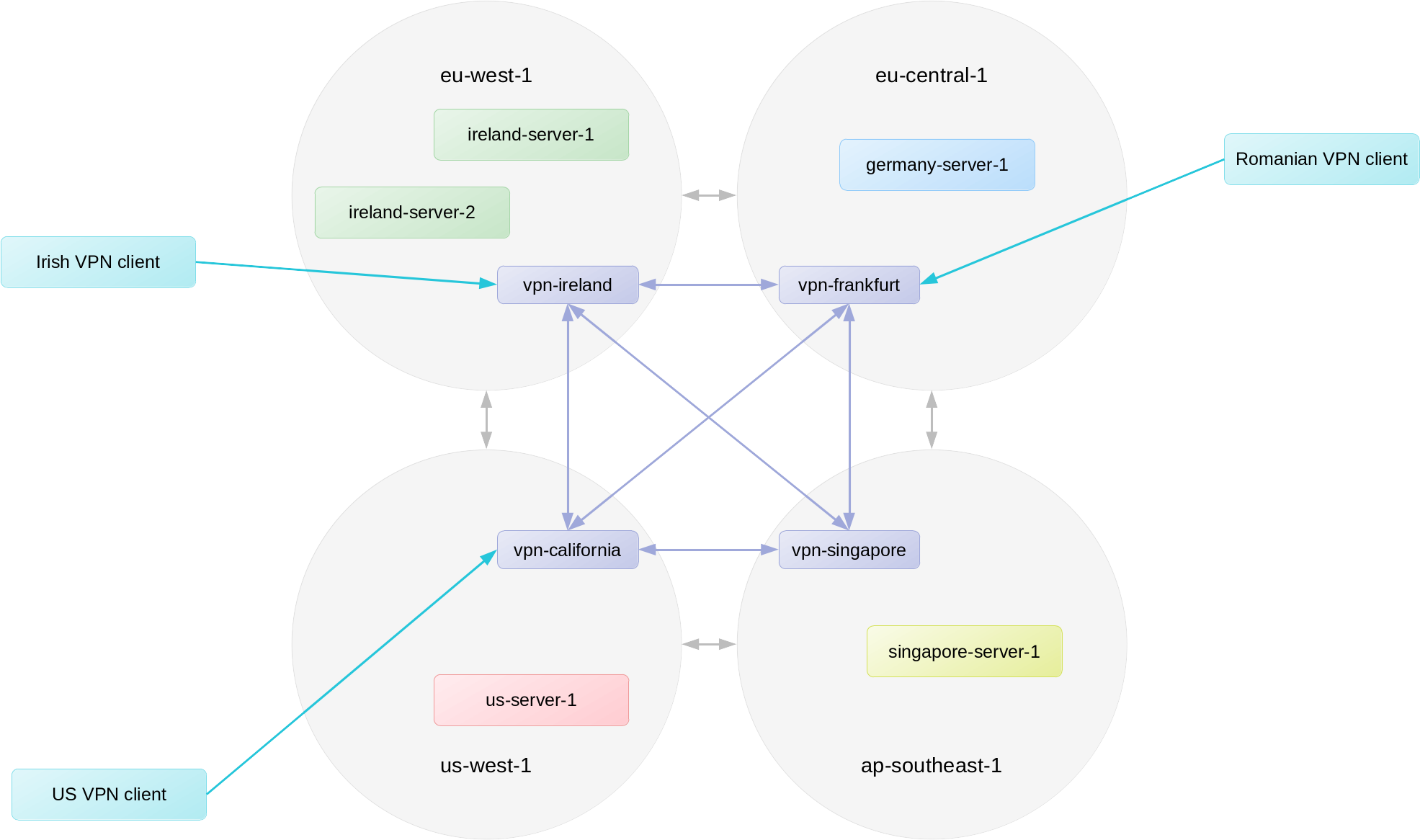
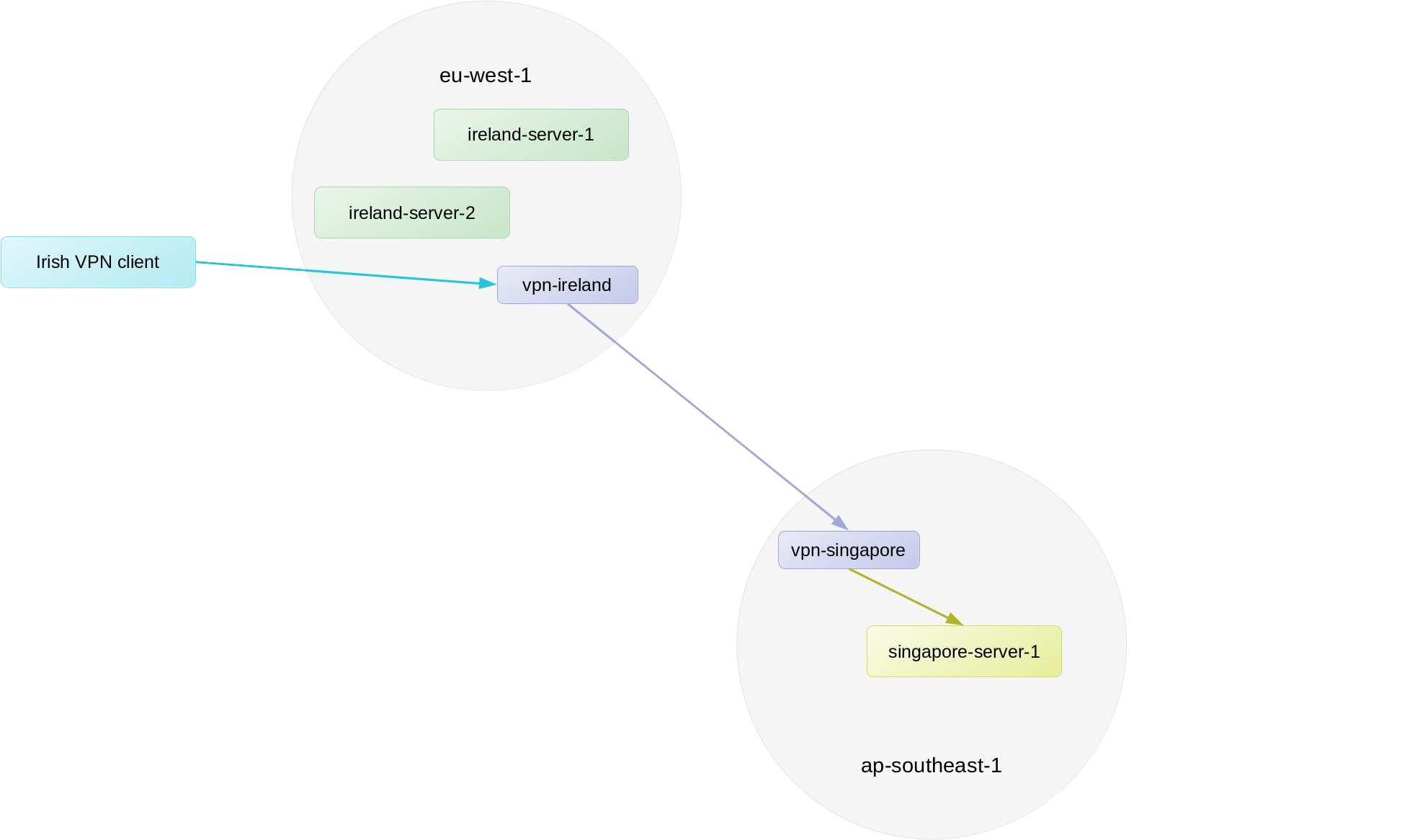
My solution was to setup a VPN server (mostly t3.nano instances) in each region that we have servers. These VPN servers communicate with each other over a “backbone” VPN interface, where they forward traffic from the VPN client to the appropriate VPN server for the region. So, for example, if a VPN client connected to the vpn-ireland server wanted to connect to a server in the ap-southeast-1 region, the vpn-ireland server would forward the traffic to the vpn-singapore server, which would then send the traffic into our ap-southeast-1 VPC. The server in the VPC would respond, and since its target is a VPN address, the traffic would go back to the vpn-singapore server, which would send it back to vpn-ireland, which would then pass it back to the VPN client.
I then wrote a simple script to run on the VPN servers to compare each client’s latest handshake with the other VPN servers and automatically route traffic to the appropriate server. This led me to my final optimization. I did some investigation, and Amazon has product, the AWS Global Accelerator that allows you to forward a single public IP address to different servers in different regions, depending on where the client connecting to the IP is located. Because Wireguard is stateless, this allows us to have clients automatically connect to the closest VPN server, and, within about five seconds, all the VPN servers will be routing traffic appropriately.
Using the Singapore example above, this setup allows our non-AWS Singapore server to once again ping a server in AWS region ap-southeast-1 with a latency of 3 ms, without affecting its latency to Ireland in any significant way. And the best part is that we don’t have to tell the Singapore server which VPN server is closest. It goes to the closest one automatically.
Building the VPN
To setup your own multi-region Wireguard VPN network, do the following. Note that we use ansible to do most of it.
- Setup a VPC in each region you care about. For each VPC, setup a peering connection with all of the other VPCs. Make sure each VPC uses a different subnet (I’d suggest using something like 10.1.0.0/16, 10.2.0.0/16, etc). Creating a VPC is beyond the scope of this blog entry.
- Setup a t3.nano instance in each region you care about in the VPC you created above. I would suggest using a distribution with a new enough kernel that Wireguard is built-in, something like Fedora. Make sure each instance has an Elastic IP.
- Verify that each VPN server can ping the other VPN servers using their private (in-VPC) IPs
- Turn on IP forwarding (
net.ipv4.ip_forward=1) and turn off the return path filter (net.ipv4.conf.all.rp_filter). Also, make sure to disable the “Source destination check” in AWS. - Setup a new route table called backbone in
/etc/iproute2/rt_tables - Open up UDP ports 51820-51821 and TCP port 51819 in the firewall.
- Setup a “backbone” Wireguard interface on each VPN server, using the config here as a starting point. Each server must have a unique key and unique IP address, but they should all use the same port. Each server should have entries for all the other servers with their public key and (assuming you want to keep AWS traffic costs down) private IP address.
AllowedIPsfor each entry should include the server’s backbone IP address (10.50.0.x/32) and the server’s VPC IP range (10.x.0.0/16). This will allow traffic to be forwarded through the VPN server to the attached VPC. Ping the other VPN server backbone IP addresses to verify connectivity over the VPN. - Add the backbone interface to your firewall’s trusted zone
- Setup a “client” Wireguard interface on each VPN server, using the config here as a starting point. This should contain the keys and IP addresses for all your VPN clients, and should be identical on all the VPN servers
- Start the
wg-routeservice from wg-route on GitHub on all the VPN servers. The service will automatically detect the other VPN servers and start exchanging routes to the VPN clients. Please note that the VPN server time needs to be fairly synchronized on all the VPN servers - Connect a VPN client to one of the VPN servers. Within five to ten seconds, all the servers should be routing any traffic to that VPN client through the server that it’s connected to. Test by pinging the different VPN server’s backbone IP addresses from the client
- Start the
wg-statusservice from wg-route on GitHub on all the VPN servers. This service will let the Global Accelerator know that this VPN server is ready for connections - Setup an AWS Global Accelerator and add a listener for the UDP port setup in your “client” Wireguard interface. For the listener, add an endpoint group for each region that you’ve setup a VPN server, with a TCP health check on port 51819. Then, in each endpoint group, add the VPN server in the region as an endpoint.
- Point your VPN client to the Global Accelerator IP. You should be able to ping any of the VPN servers. If you login to one of the VPN servers and run
journalctl -f -u wg-route -n 100, you should see a log message telling which VPN server your client connected to.
Problems and limitations
- If you bring down a VPN server (by running
systemctl stop wg-status), any clients connected to that server will continue to stay connected to that server until there’s been 30 seconds of inactivity on the UDP connection. If you’re using a persistent keep-alive of less than 30 seconds, that means the client will always stay connected, even though a new client will bee connected to a different server. This is due to a bug in the AWS Global Accelerator, and, according to the Amazon technician I spoke to, they are working on fixing it. For now, a script on the VPN client that re-initialized the UDP connection when it’s unable to ping the VPN server is sufficient. - If a VPN server fails, the VPN clients should switch to another VPN server (see the limitation above), but they will be unable to access any servers in the VPC that the failed VPN server is in. There are two potential solutions. Either move all servers in the VPC onto the VPN, removing the speed and cost benefits of using the VPC, or setup a network load balancer in the VPC, and spin up a second VPN server. Please note that the second solution would require some extra work on backbone routing that hasn’t yet been done.
