
PinePhone call quality
I bought a PinePhone a couple of months ago, mainly for the opportunity to play with it and see what it could do. Since I work for a company that does voice call quality testing, the first thing I wanted to do was figure out how to play back our audio quality test files and then do some call audio quality tests.
When doing call audio quality testing, it’s very important that the audio you’re playing back not be transcoded or even resampled, so using PulseAudio or PipeWire was completely out of the question. Figuring this process out turned out to be far harder than I expected, so I thought I should document how I made it work. My background is in IT infrastructure, and I am not an audio engineer or a telephony expert, so I wouldn’t be surprised if there are better ways of doing things. Suggestions are very welcome on Twitter or via email.
How to play audio over a call
- Insert your SIM into the phone. Then, setup Fedora on a microSD card and boot it
- Connect to the network either using wifi or a dock
- Make sure to enable
sshd.serviceif it’s not already enabled. Then SSH into the PinePhone (default username ispineand default password is123456), and become root (sudo su) - Install asterisk
dnf -y install asterisk - Build and install the Quectel asterisk module. To build the channel module, you’ll need to download the source RPM for the asterisk package installed in step 4, build it (at least to the point where it’s generated the
includefiles), and then pass the build directory to./configure --with-asterisk=... - Copy
qeuctel.confto/etc/asterisk. The defaults should suffice - Stop
phosh.serviceandModemManager.service - Setup an extension in
/etc/asterisk/extensions.confwith the name[incoming-mobile]. This is what any incoming calls will be directed to. For testing, I suggest renaming the[demo]section to[incoming-mobile] - Add the
asteriskuser to theaudioanddialoutgroups - Set the audio mode to Voice call in ALSA by running
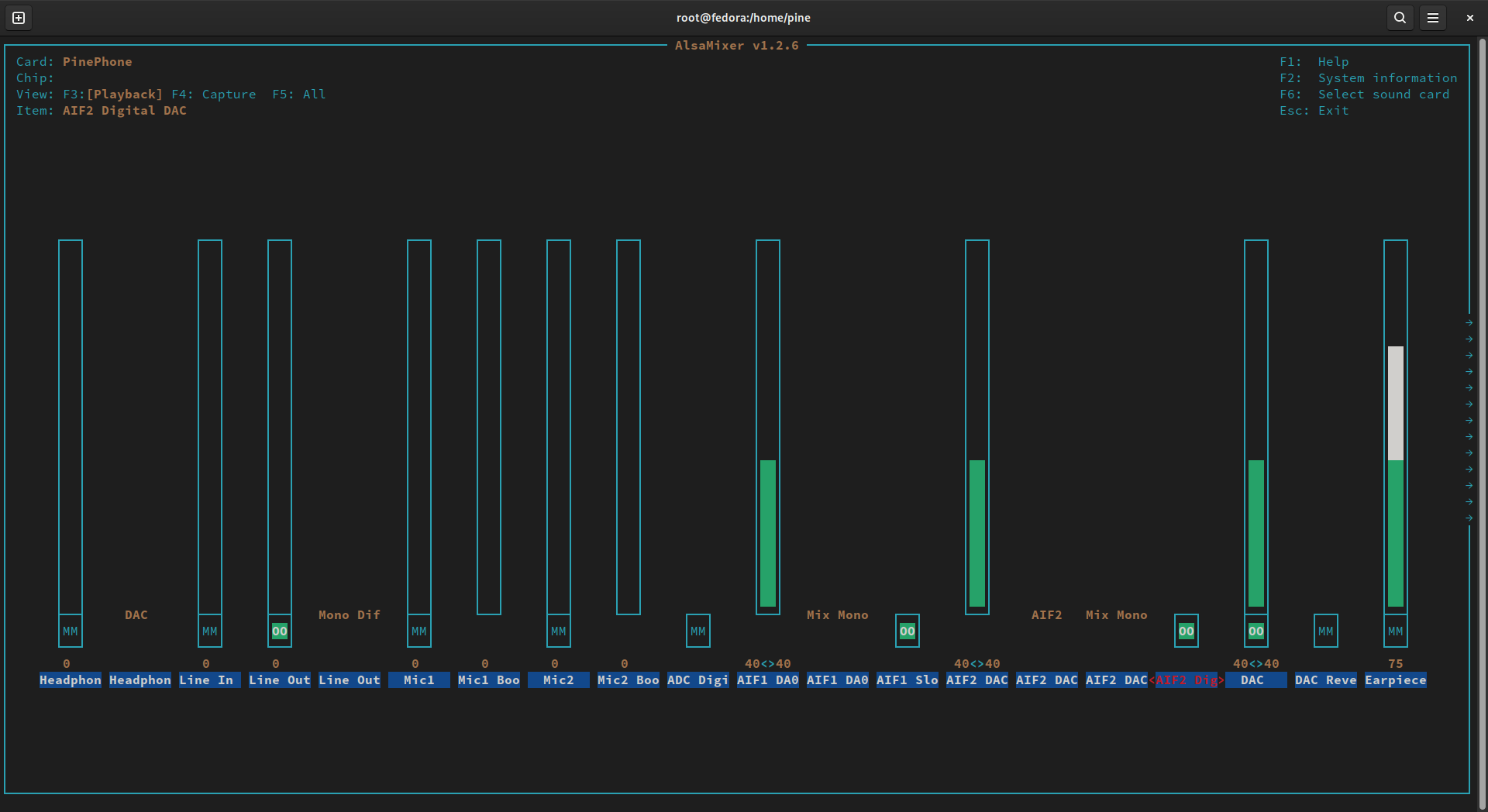
alsaucm -c PinePhone set _verb 'Voice Call'. (Rather embarrassingly, this step took me days to figure out!) - In the playback tab of
alsamixer, make sure thatLine Outis unmuted (even if the volume is at 0%), along withAIF1 Slot 0 Digital DACandAIF2 Digital DAC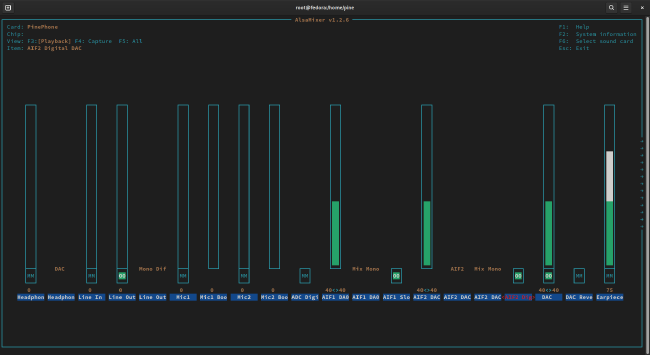
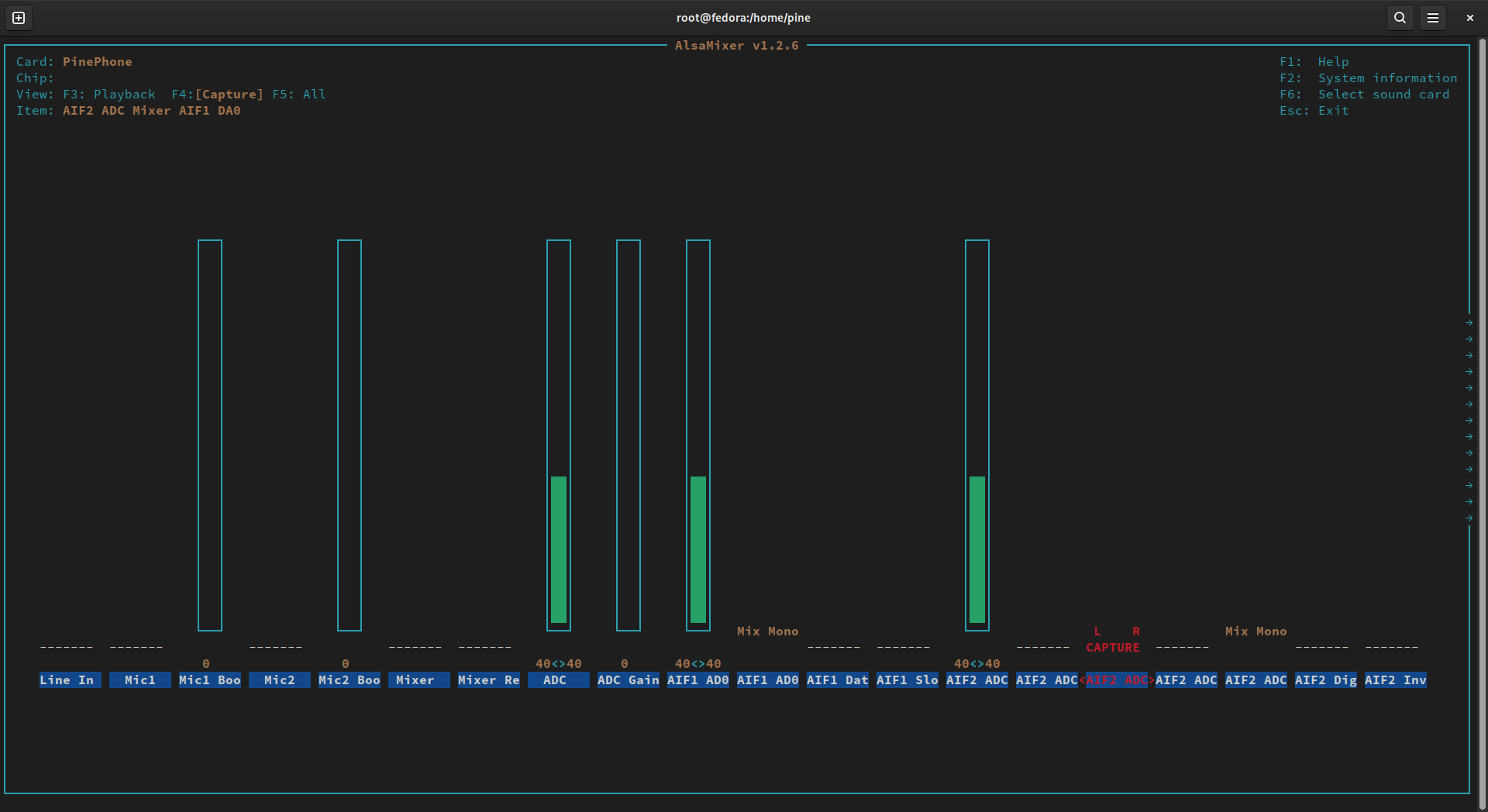
- In the recording tab of
alsamixer, disable recording forAIF1 Data Digital ADCandAIF2 ADC Mixer ADC. Then, enable recording forAIF2 ADC Mixer AIF1 DA0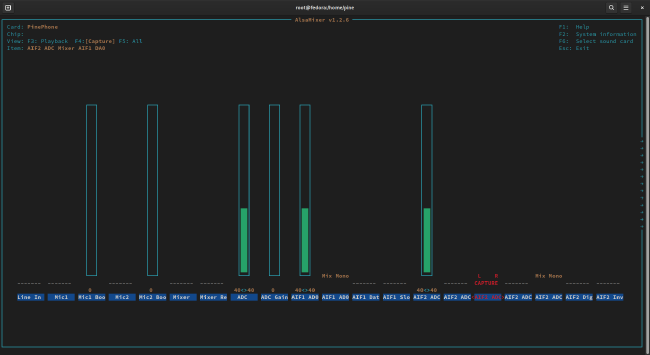
- Start
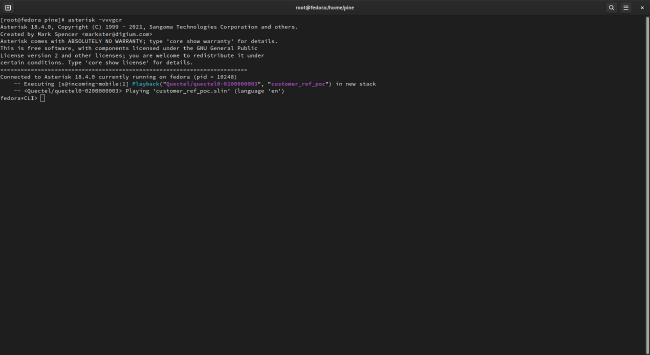
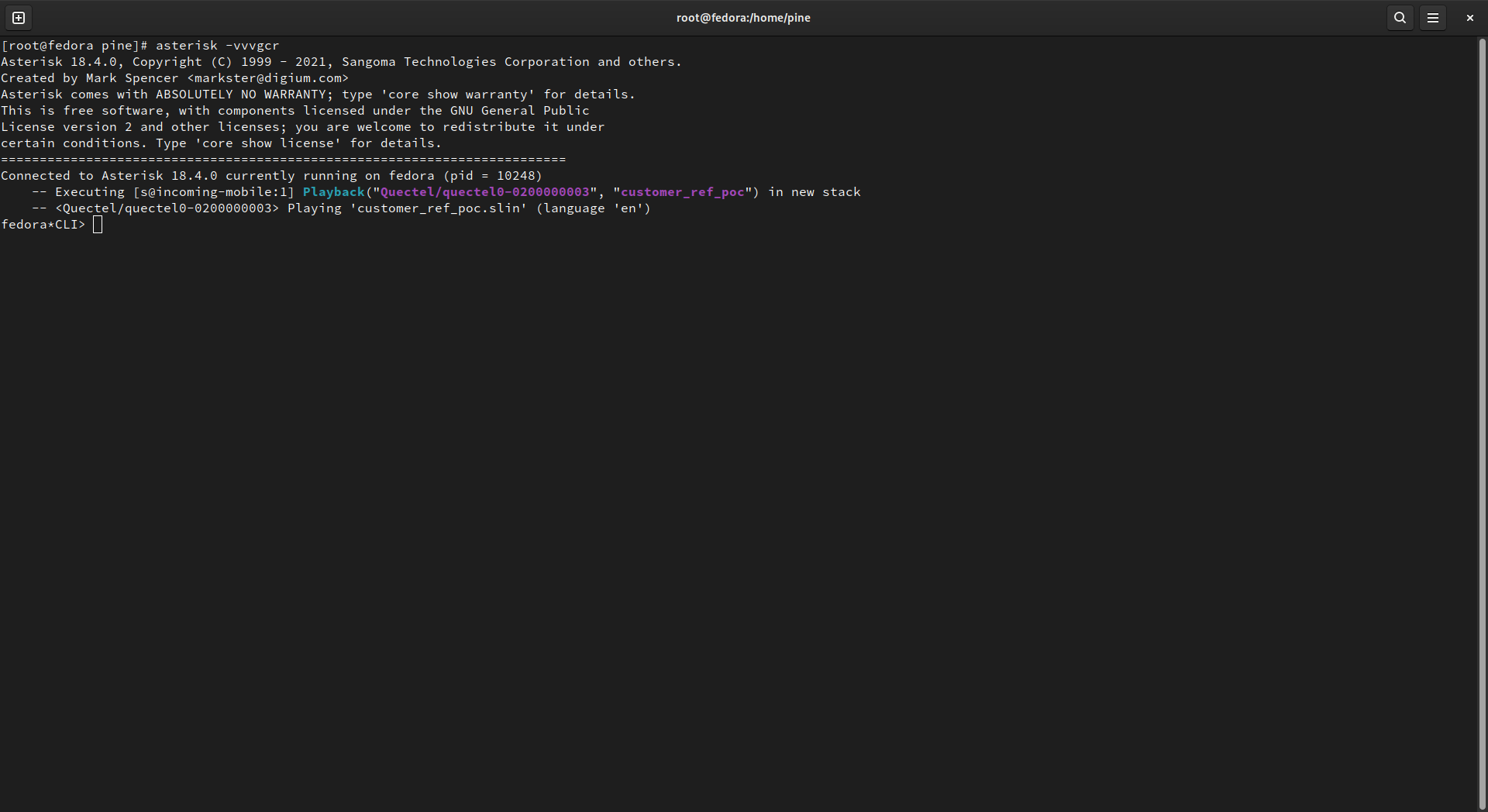
asterisk.service - Run
asterisk -vvvcgr - Call your PinePhone’s number from another phone. On the other phone, you should hear the Asterisk demo (or whatever other audio you configured to play), and on the PinePhone, you should see something like this:
How the PinePhone modem routes audio
(short answer: Magic!)
Figuring out steps 10-12 above was a great example of 10% of the work taking 90% of the time. This section explains what I think is going on here, but a lot of it is guesswork. Unless you’re interested in the inner workings of the PinePhone and its modem, feel free to skip this section.
It didn’t take long for me to figure out how to build asterisk and the Quectel channel module, and, when I placed my first call after starting up asterisk, I was plenty excited when the call went through, Asterisk picked up… and then silence! Roughly 30 seconds of silence (oddly enough, the length of the file I was playing), and then asterisk hung up.
It became clear to me that asterisk thought it was playing audio, even if it wasn’t actually making it to my other phone. Thus started days of experimentation, trying to figure out the problem.
The PinePhone has a Quectel EG25-G LTE modem in it that, by default, provides a number of USB serial devices, one of which (supposedly) is where we’re supposed to send and receive audio.
After loads of scattered documentation around the internet (fun fact, the Quectel EC25 modem has some very different features, so you can’t just assume its manual applies to the EG25-G), it became more and more clear that, for voice calls, the PinePhone’s modem is tied into the PinePhone’s DSP, which is exposed in Linux through ALSA. AIF2 is the modem’s voice channel while AIF1 is the PinePhone’s normal audio DAC.
It took lots of experimentation to work out that, to get audio from the USB serial device to actually get sent through the modem, you need to route AIF1’s output audio into AIF2 (which is what we’re doing in step 12). You also need to enable the AIF1 and AIF2 DACS (step 11), and make sure that Line Out is unmuted.
The strange thing is that, even though we’re using ALSA to enable a number of different switches, none of the volume levels have any effect on the volume sent through the modem. I suspect that this is because Asterisk is already sending the exact audio data without any processing.
One limitation our current system has is that it only transmits audio in 8KHz, which means we haven’t yet been able to test VoLTE. From what I can see, the EG25-G supports VoLTE, but I’ll need to do more research to figure out how to turn it on.
Call quality
So, now that we can play audio through Asterisk, what does the actual call quality look like?
At Spearline, we commonly use PESQ to test a call’s audio quality, and we’ve got a great summary of what PESQ is and what the scores actually mean here. We ran two sets of tests on the PinePhone, one when the phone was in Spearline’s headquarters, and the other when it was in my home (a couple of kilometers away from the office).
This first chart shows the PESQ scores when the phone was at Spearline’s headquarters.
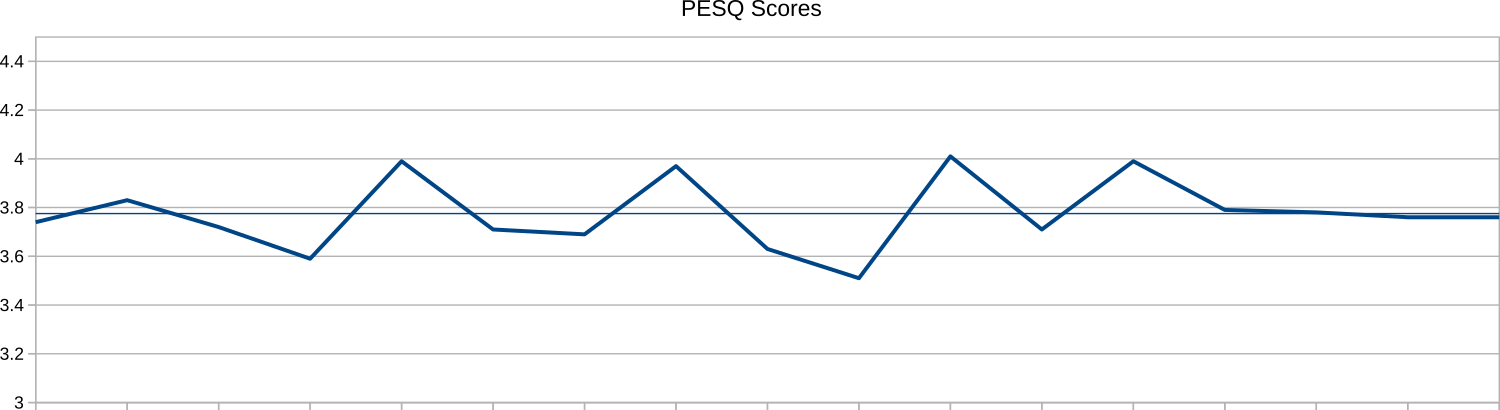
The scores vary from 3.51 to 4.01 with an average of 3.78, which puts them at the top end of the second-highest band of PESQ scores: 3.30-3.79 Attention necessary: no appreciable effort required. In other words, a call placed to the PinePhone while in Spearline’s headquarters would sound good, but you would have to put in a very small amount of effort to pay attention.
This second chart shows the PESQ score when the phone was moved to my home.
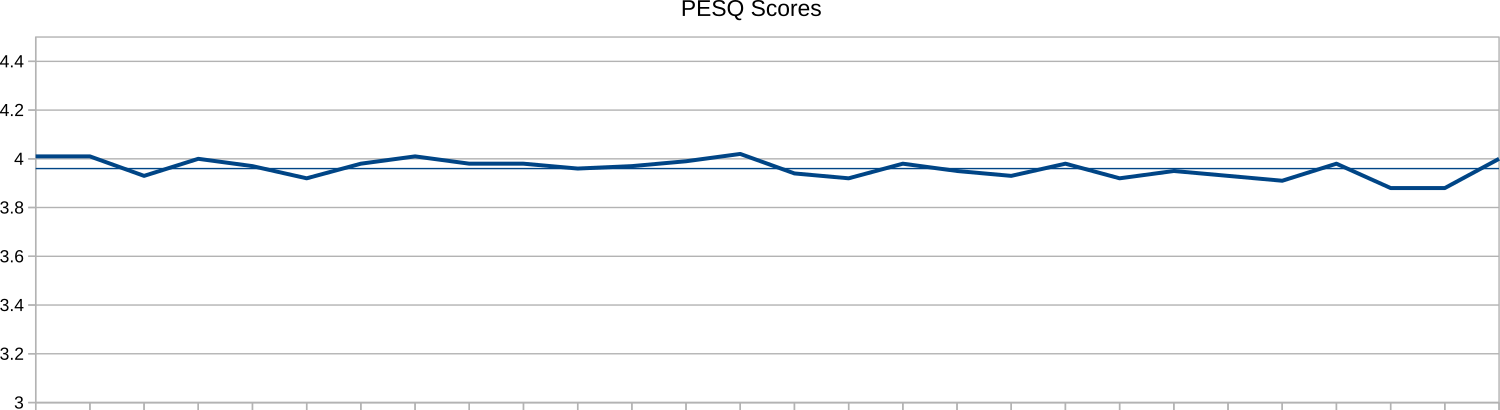
Here the scores were higher and more consistent, ranging from 3.88 to 4.02 with an average of 3.96, which puts them in the highest band of PESQ scores: 3.80-4.50 Complete relaxation possible; no effort required. In other words, a call to the PinePhone at my home would result in a call where the conversation could be completely relaxed, with no strain to understand what the other person is saying.
This shows that, as expected, call quality will depend on the tower you’re connected to and the distance to the tower. However, both sets of scores are high enough to make it clear that the PinePhone is fully capable of making high quality audio calls.
Photo Pinephone betaedition by ICCCC used under the CC0 license

{kind=link}