
On binary delta algorithms
Yesterday I was reading this update (warning: still subscriber-only) on the Courgette delta algorithm that will be used by Google to push Chrome updates.
The article focused on potential patent problems with the Courgette method, but also described how the Courgette method works and also suggested that deltarpm (which I maintain in Fedora) could learn from it.
While not wanting to argue that particular point (I would love to get a hold of the code and see how much it would actually help our deltarpms), I do want to correct a couple of misconceptions about deltarpm.
Courgette, deltarpm and bsdiff (the tool) are all based on the bsdiff algorithm, which is very efficient. The problem comes when dealing with binaries. One small change in the source code will normally result in many small changes through the binary as the locations of pointers change.
(In the graphs provided, location two is a byte of data that has changed, while locations 3-6 and 21-24 represent two relative jump pointers to the same location. In the new binary, the location has changed by 74 bytes.)
The first graph is that of a naive delta using the bsdiff algorithm.
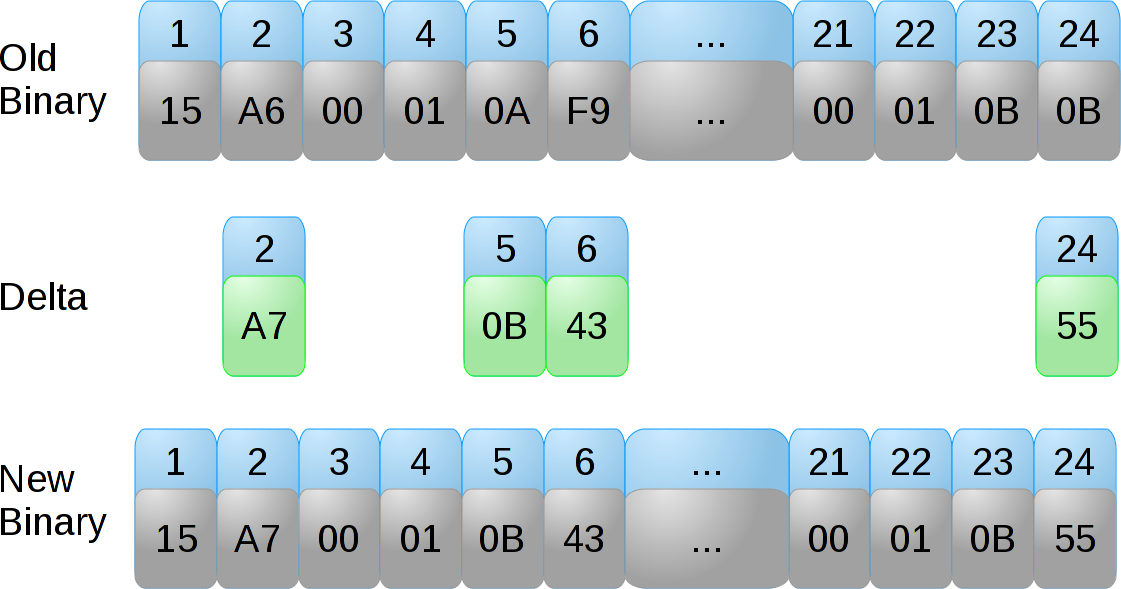
Note that the delta is four bytes of not-very-compressible data (out of 12). Not so great.
The second graph is roughly what courgette does with the same data. It does some disassembly to convert the relative pointers into labels. When applying the delta, courgette will disassemble the old file, apply the delta, and then reassemble the resulting not-quite-machine code into machine code.
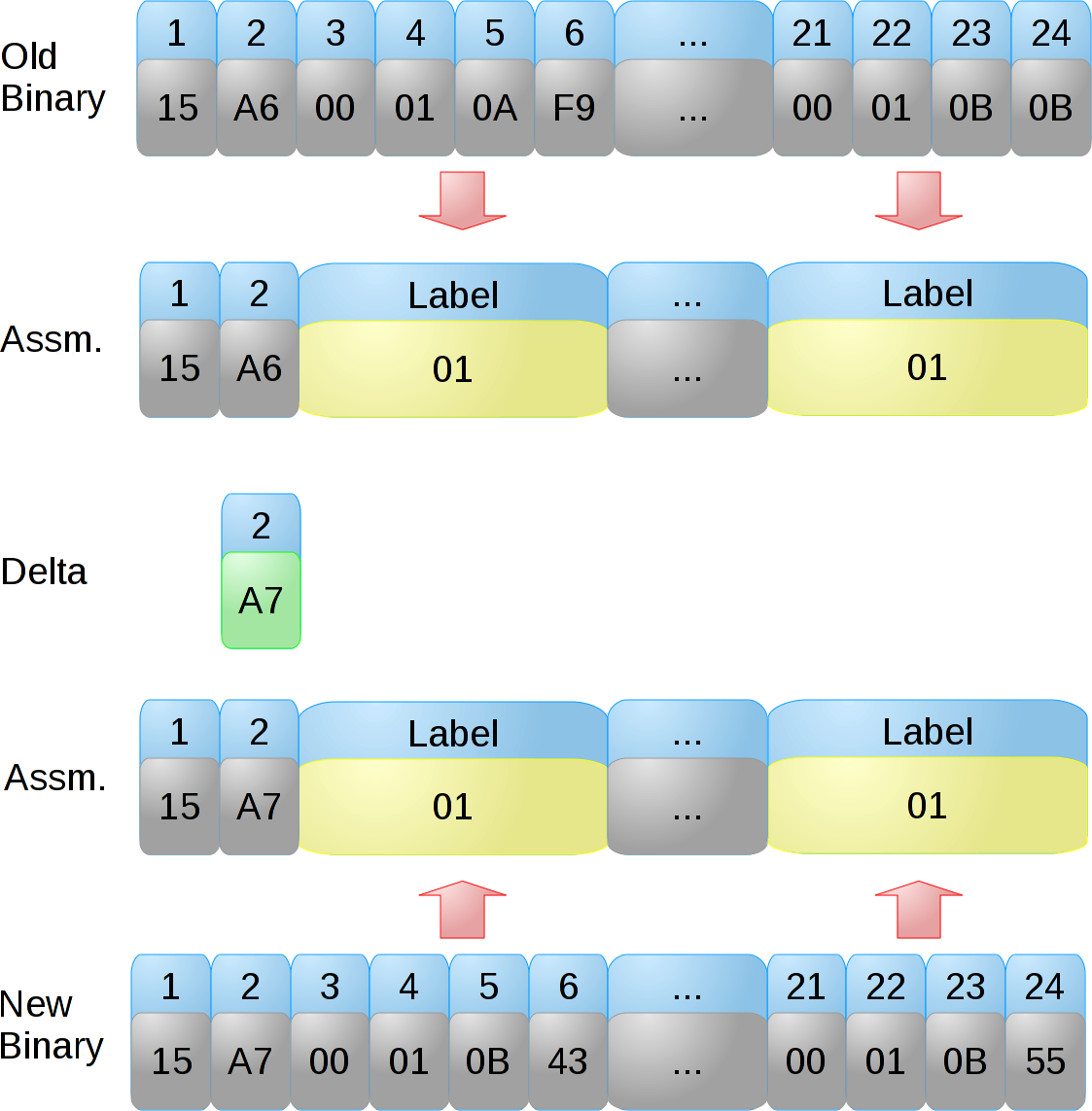
Note that we’re down to a one-byte delta! Wonderful!
Now, the final example is how both the bsdiff tool and deltarpm work. They use the algorithm Colin Percival describes here which has an interesting twist when dealing with binaries.
When the locations change in a binary, they tend to do so in a consistent way. As deltarpm is doing its comparison, it adds an extra step. If less than half of the bytes in a segment have changed, deltarpm will do a byte-wise subtraction of the old binary’s bytes from the new binary’s bytes. This is then stored in an “add block”, which will mostly contain zeros.
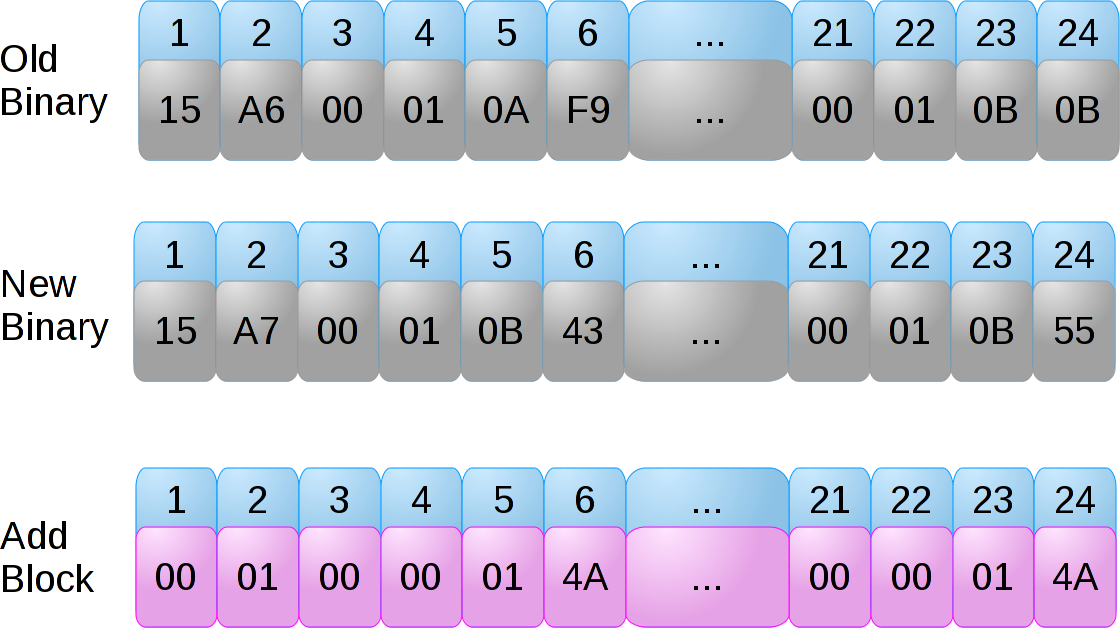
While this does give us a block the size of the old binary, this block is very highly compressible (especially using bzip2).
While we may not be getting the compression levels that we might using courgette, we are doing far better than we would be using a naive bsdiff algorithm.
While courgette obviously has the advantage of size, it’s primary disadvantage is that it is very archicture-specific. The algorithm must know how to both assemble and disassemble binaries for each architecture it’s built for.
The advantage of the “add block” method is that it is generic to all architectures, but its disadvantage is that it won’t reach the same delta levels as courgette.
Having said that, I still haven’t had a chance to do any direct comparisons, which may tell us how much better courgette is than deltarpm.
(Updated: Tried to make it clear that bsdiff (the tool) doesn’t just use a naive bsdiff algorithm)
Comments
ferringb
Saturday, Nov 7, 2009
You might want to be a bit clearer in your phrasing here- bsdiff (the tool percieval implemented) already does “overlayed add"s too. Not a great name for it, but about the best I could come up for the encoded command when I was adding bsdiff format support to diffball.
Took a couple of read throughs of this blog before I figured out you weren’t calling bsdiff, the tool, naive, you were referring to the raw algorithm rather then the actual bsdiff tool.
Jonathan Dieter
Saturday, Nov 7, 2009
My apologies. On http://www.daemonology.net/bsdiff, it looks like bsdiff the tool never implemented the add block (or overlayed adds), but I really should have confirmed that.
I will clarify this in the blog entry.
ferringb
Saturday, Nov 7, 2009
Technically it’s more of an overlayed copy thinking about it, but yeah.
Certainly confused the crap out of me when I first spotted it in the code though (goofy trick, but the overhead of it when compression is added is insanely low compared to your normal delta format commands).